
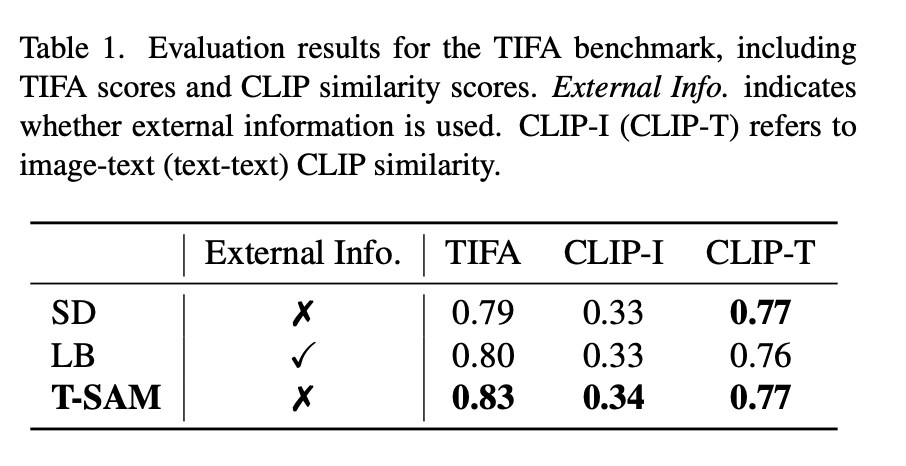
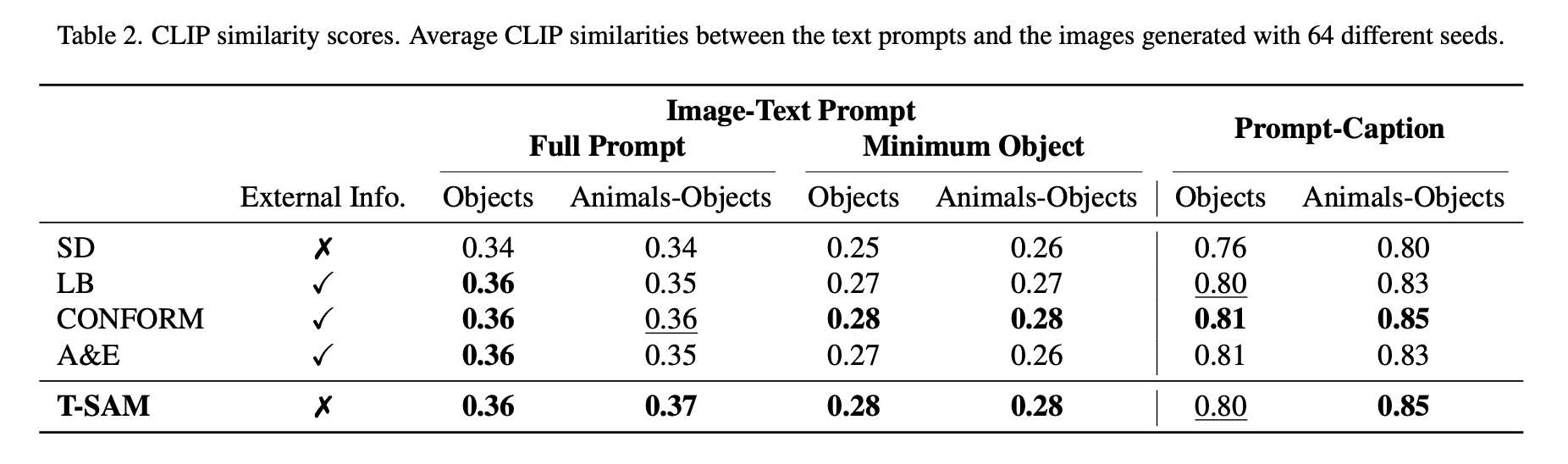
In text-to-image generation, the image often fails to faithfully represent the content in the input text. We developed novel a method (T-SAM) to mitigate this problem which is:
training-free, free of external input, and theoretically sound.
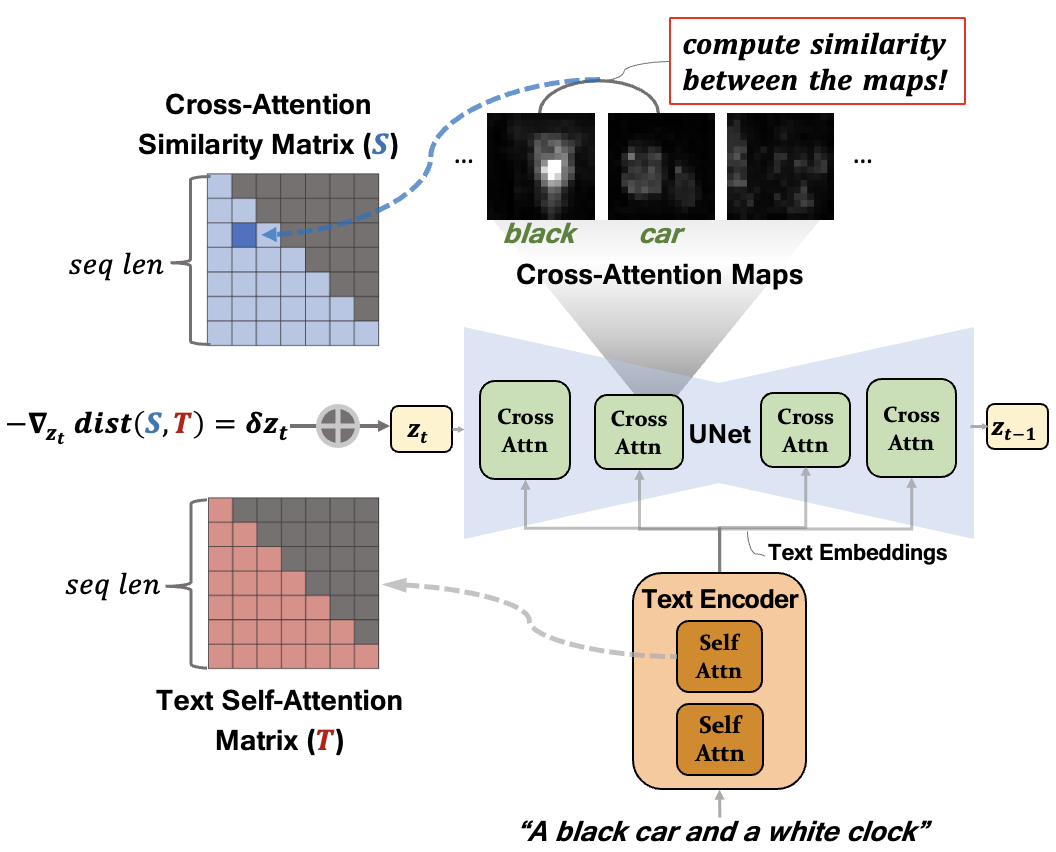
In text-to-image diffusion models, the cross-attention map of each text token indicates the specific image regions attended. Comparing these maps of syntactically related tokens provides insights into how well the generated image reflects the text prompt. For example, in the prompt, "a black car and a white clock", the cross-attention maps for "black" and "car" should focus on overlapping regions to depict a black car, while "car" and "clock" should not. Incorrect overlapping in the maps generally produces generation flaws such as missing objects and incorrect attribute binding. Our study makes the key observations investigating this issue in the existing text-to-image models:(1) the similarity in text embeddings between different tokens -- used as conditioning inputs -- can cause their cross-attention maps to focus on the same image regions; and (2) text embeddings often fail to faithfully capture syntactic relations already within text attention maps. As a result, such syntactic relationships can be overlooked in cross-attention module, leading to inaccurate image generation. To address this, we propose a method that directly transfers syntactic relations from the text attention maps to the cross-attention module via a test-time optimization. Our approach leverages this inherent yet unexploited information within text attention maps to enhance image-text semantic alignment across diverse prompts, without relying on external guidance.
In a nutshell, out method regularizes cross-attention maps in diffusion models based on the self-attention matrix in the text encoder.
Our observations are summarized in the following plots. We show that text embeddings fail to encode the syntactic relationships between words. In contrast, the self-attention matrix of the text encoder reflects those relationships.
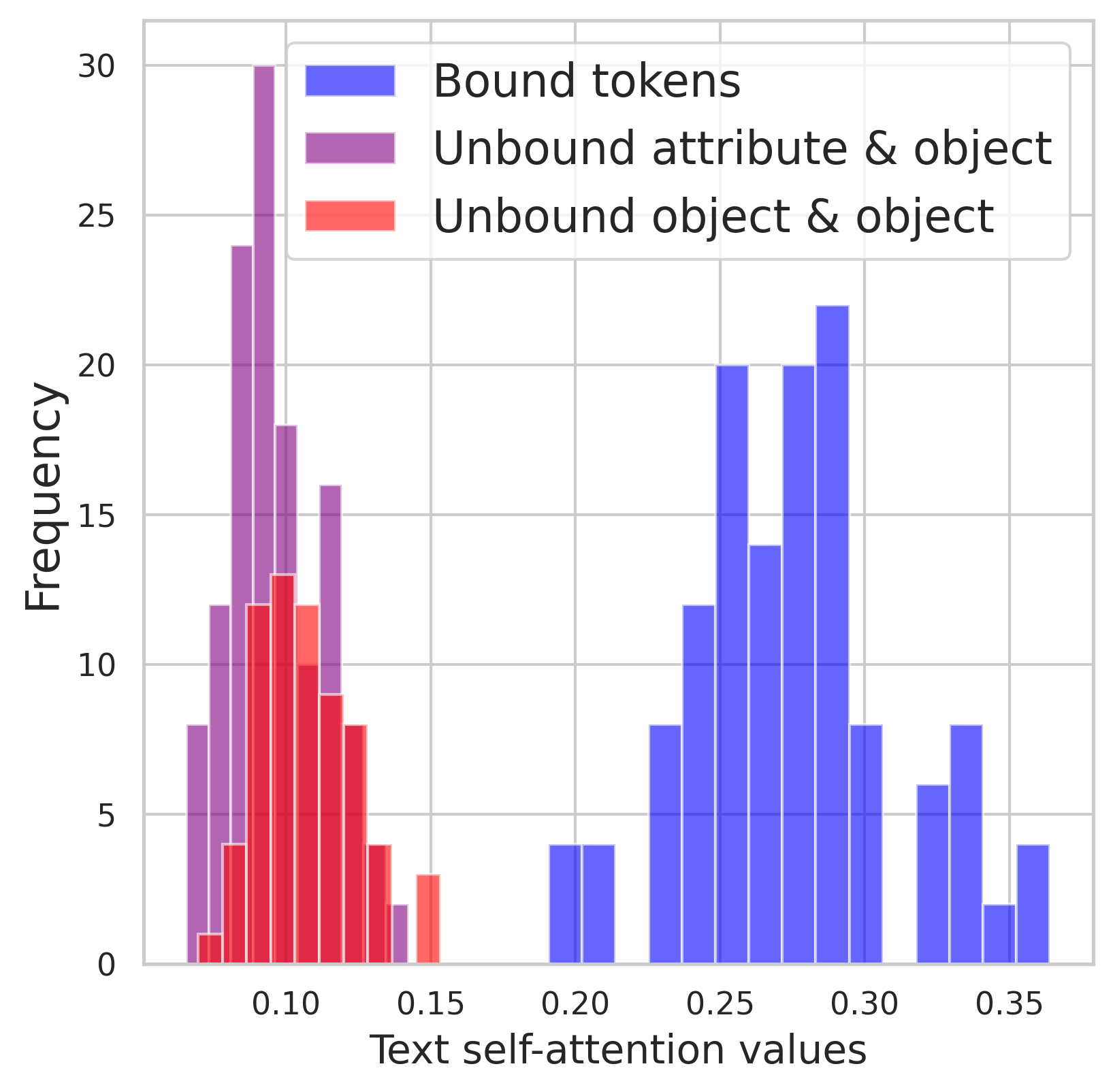
The distributions of text self-attention value for bound tokens vs. unbound tokens. The separate distributions indicate text self-attention maps can indeed represent the syntactic relationships.
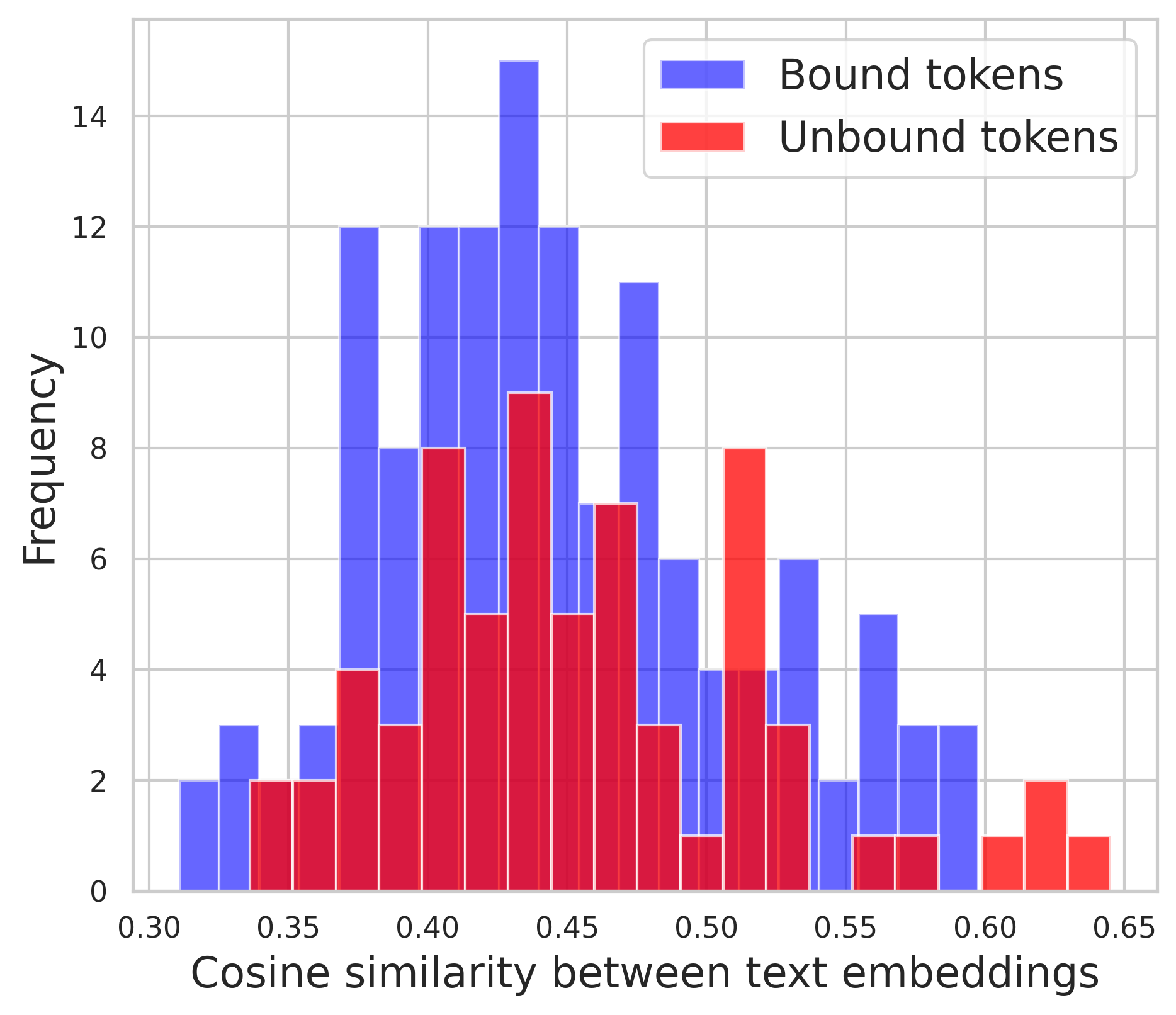
The distributions of text embedding similarity between i) Bound tokens, and ii) Unbound tokens. The distributions show no discernible difference, indicating text embeddings do not effectively represent the syntactic relationships.
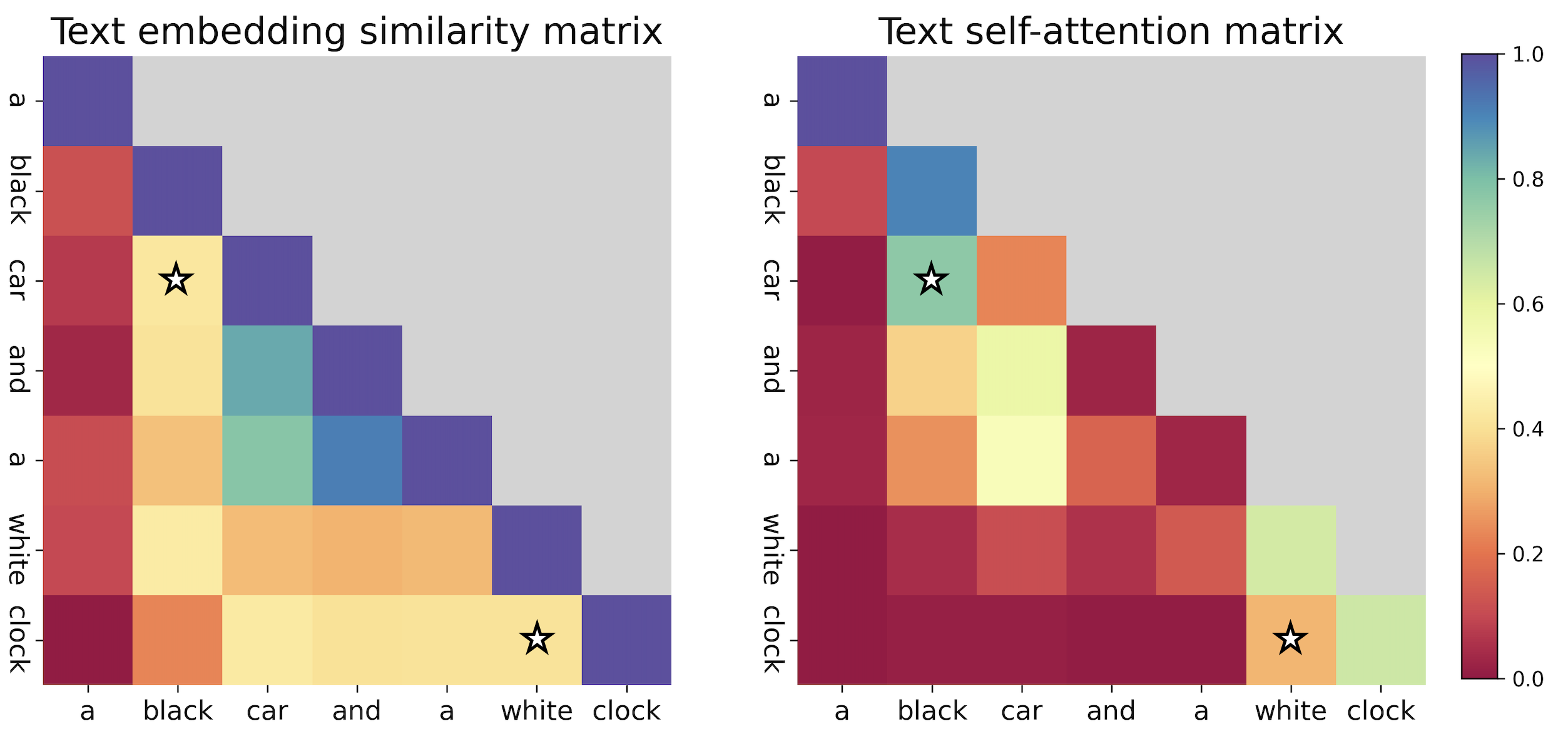
Comparison of text embedding similarity (left) and the text self-attention map power by 3 (right) for the prompt "a black car and a white clock". In the self-attention maps, "clock" attends more to "white", unlike the text embeddings.
Our method outperforms baseline methods as shown below.

@article{kim2024text,
title={Text Embedding is Not All You Need: Attention Control for Text-to-Image Semantic Alignment with Text Self-Attention Maps},
author={Kim, Jeeyung and Esmaeili, Erfan and Qiu, Qiang},
journal={arXiv preprint arXiv:2411.15236},
year={2024}
}